
在這個行業中,我們都需要知道我們的行動是否會產生我們想要的結果,坦白地說,我們希望盡快知道。緩慢、反複試驗和錯誤測試的日子一去不複返了。今天,我們可以提前係統地測試我們的行為。在市場營銷中,A\B\n和多元測試已經被用於定量比較一條或多條信息相互之間的影響,以及與對照的影響,即根本沒有消息。特別是在數字營銷中,主題線測試和類似類型的副本測試從未如此容易。
但是,還有一些細節需要考慮。執行一個有意義的測試需要多少數據?經驗法則是向10%的觀眾發送信息A和10%的信息b。在測量結果後,你將“更好”的信息發送給剩下的80%。但10%就足夠了嗎?你有沒有發現有意義的區別?相反,每個測試組的10%會不會太多?你是否因為測試一條明顯低劣的信息而浪費了大量與用戶交流的機會?每條信息及其產生的響應或缺乏構成了一個可以用來學習和改進的數據點(如果你喜歡,也可以稱之為數據點)。那麼,為什麼要使用不利用這一寶貴信號的特殊規則呢?與聰明的選擇根據Braze的理論,我們可以係統地提前測試我們的行為,而不是通過嚐試和錯誤慢慢學習。
智能選擇將決定向用戶發送什麼消息視為一種Multi-Armed強盜這個著名的場景最初構思於第二次世界大戰期間。想象一下,我正站在一排裝有100枚25美分硬幣的老虎機前麵。我可以以任何順序一次玩一個機器。如果我贏了,我可以拿回一美元。否則,我什麼都得不到。問題是,所有的機器都有不同的獲勝幾率,我一開始不知道它們是多少。如果我將第1 / 4投入隨機選擇的機器並獲勝,我便會將第2 / 4投入相同的機器。但第二次,如果我輸了怎麼辦?我應該繼續在這台機器上花更多的硬幣嗎?如果第一次中獎隻是僥幸,而其他一些機器的中獎概率更高呢? I need to spend more quarters to explore the other options. Or, we can continue exploiting the machines for which we already know something about the payout probability. You can see why this is known as an exploration vs. exploitation problem, and it’s a good analogy for choosing which marketing message might be best.
這個難題有個解決方案叫做湯普森抽樣.Thompson抽樣是在人工智能的學術領域發展起來的,它首先假設所有的選項都一樣好,然後在各種選項中以相等的比例發送一些測試消息。然後,它會查看每種期權的支付曆史,並計算它們的概率。使用這些信息,它創建一個蒙特卡羅模擬-從模擬老虎機*獲得的成千上萬張虛擬圖,與目前觀察到的真實數據具有相同的統計屬性。(同樣的方法描述在《黑鏡》的一集)。然後,該算法查看這些模擬的結果,並計算出盡管我們選擇了明顯的“最佳”選項,但我們仍有多少時間會賠錢。然後,它為這些選項分配了一定比例的未來策略,盡管這些選項目前看起來較差,但由於缺乏信息,它們可能比目前看起來更好。
算法重複這個過程,直到有足夠的數據得出結論,繼續探索是不必要的,可能是浪費的。到那時,優勝者就確定了,測試也就結束了。但如果我們不確定,我們就會繼續把一定比例的劇本分配給人們不太了解的備選方案。在某些情況下,湯普森抽樣已被證明是最好的方法。它確保我減少了選擇獲勝者所需的消息數量。它還允許我盡早停止或修改我的測試,如果我知道沒有明確的贏家。
重要的是,Thompson Sampling確保我充分測試了所有的備選方案,而不會太快做出決定。在傳統的a /B測試中,人們往往傾向於選擇轉化率較高的信息並將其稱為贏家。例如,如果消息A產生了14%的轉化率,消息B產生了15%的轉化率,那麼B肯定更好,對吧?不幸的是,這並不容易。這取決於我們采樣了多少用戶,以及真正的差異(如果存在的話)有多大。這隻是另一種說法,即我們不一定知道我們觀察到的差異是否具有統計學意義。湯普森抽樣確保我們在新數據塊傳入時將其納入,更新我們對每條信息有效性的理解,並繼續這樣做,直到我們有一個數學上合理的贏家來選擇。
Braze的解決方案讓數據告訴我需要多少測試,而不是使用基於不可靠的經驗規則的假設。有了智能選擇,我可以確定我正在盡可能快地學習我的選擇,並確保盡可能多的用戶得到正確的信息。
*額外的細節好奇
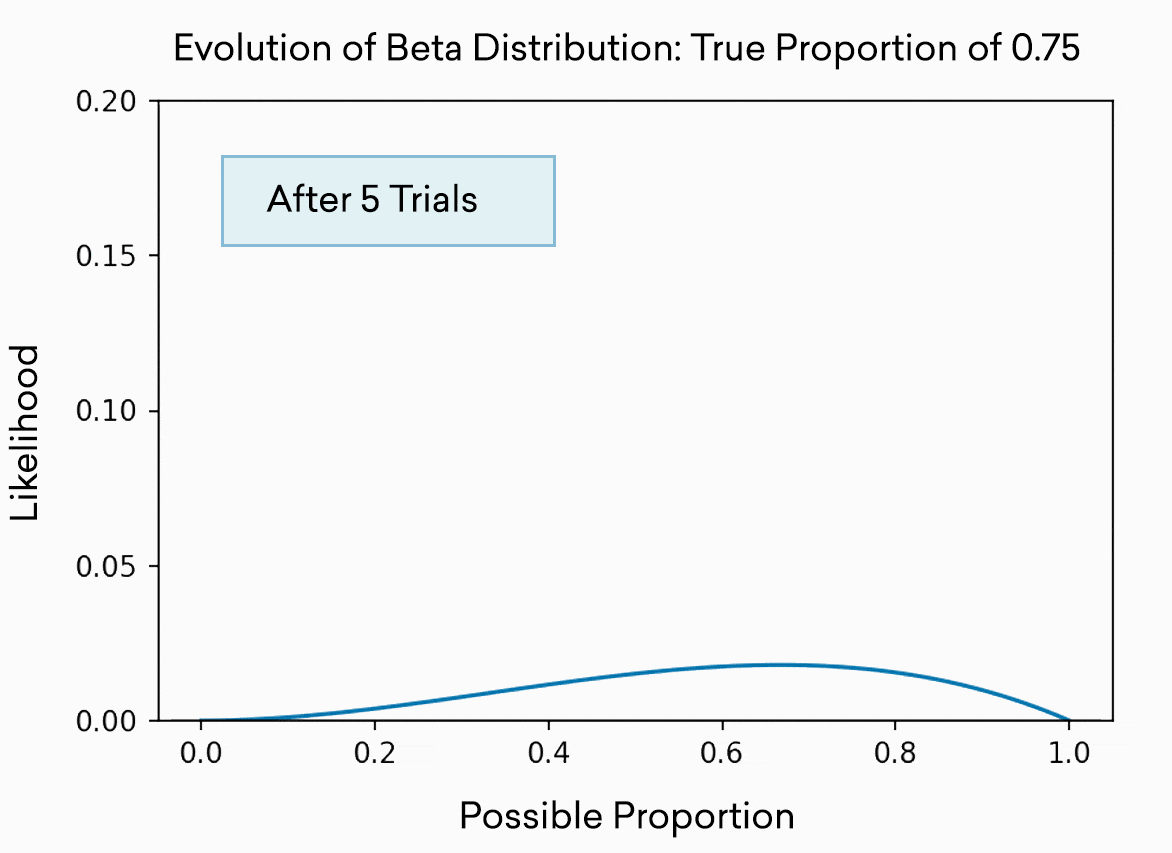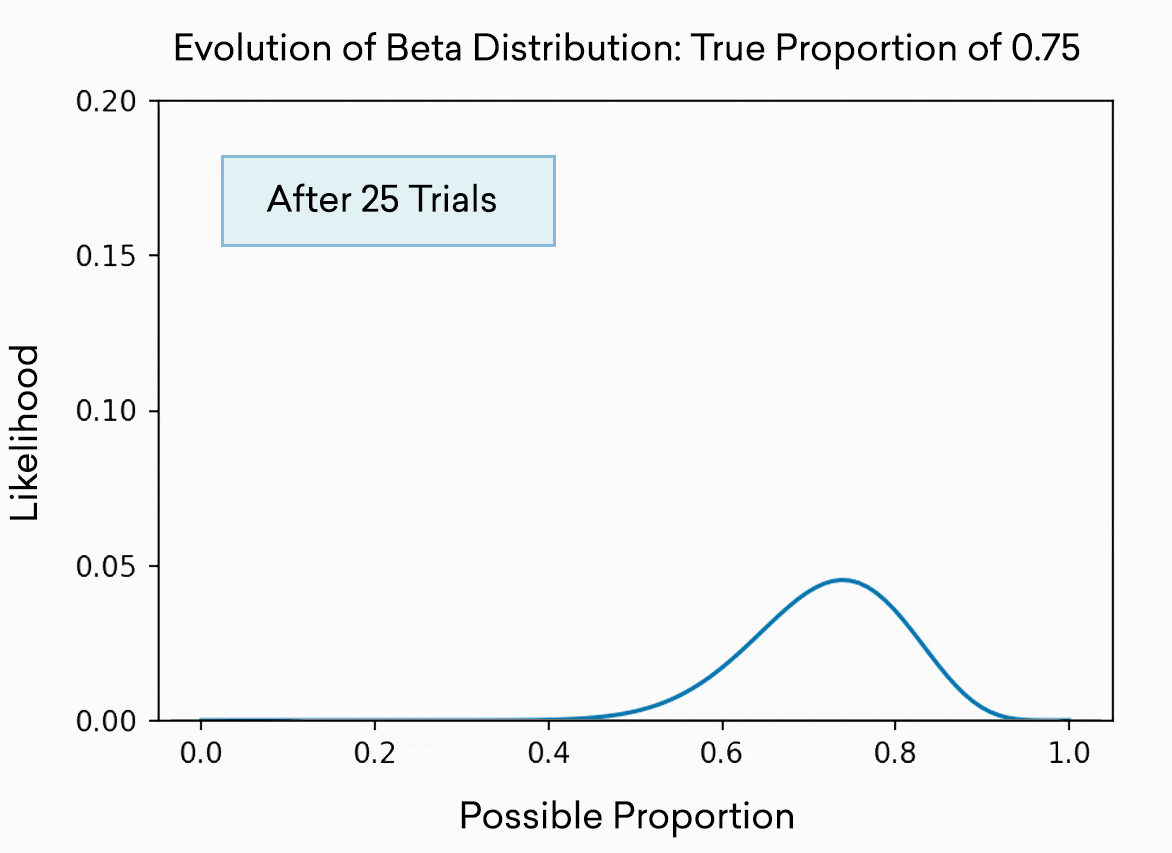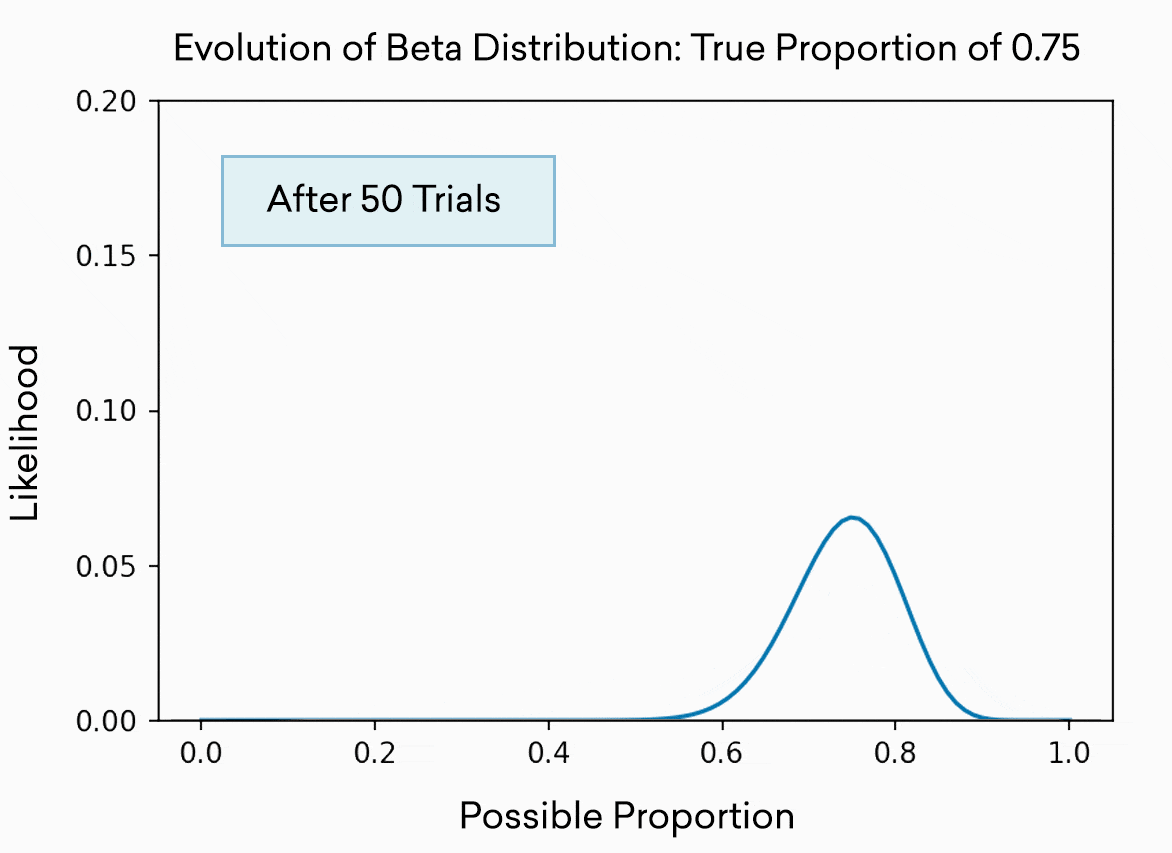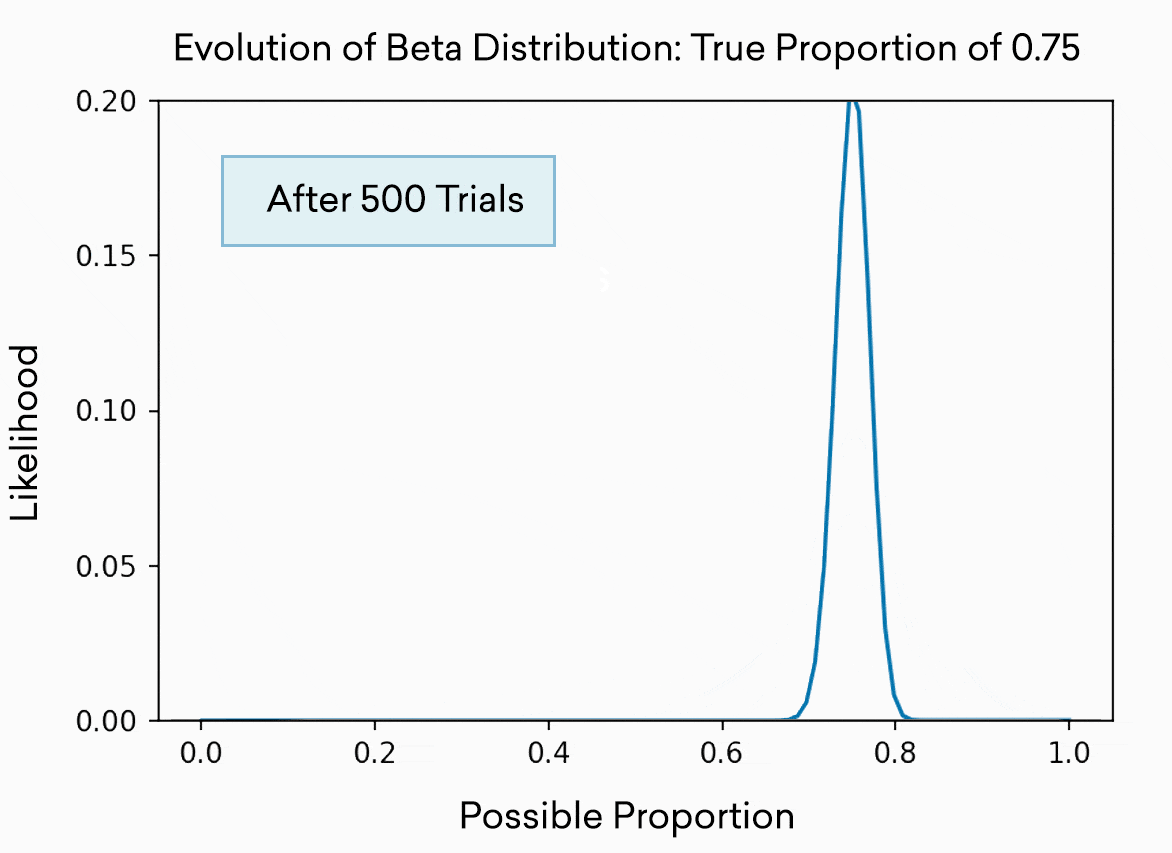
每個老虎機都被模擬為beta分布的拉力。這種分布通常用來表示對比例或百分比的最佳猜測。正如您所預期的那樣,您進行的試驗越多,您對“真實”或“真實”百分比的了解就越準確,因此分布也就越窄。分布實際上是現有證據表明真實百分比可能存在的範圍。一開始,僅僅經過5次試驗,它幾乎可以是0到1之間的任何位置,我們對任何一個位置的置信度(y軸上的高度)都很低。經過500次試驗,我們非常確定真正的比例在0.7到0.8之間。當然,在這個玩具的例子中,我們知道百分比,因為我們把它設為0.75。
有興趣在Braze工作嗎?查看我們目前的職位空缺!
更多關於Building Braze







