
Braze每天代表客戶處理數以億計的事件,從而將數十億條高度集中的個性化消息發送給最終用戶。manbetx万博全站客户端如果沒有發送這些信息,可能是錯過了收據,或者更糟糕的是錯過了通知,讓用戶知道他們的食物已經準備好了。為了確保這些關鍵消息總是正確和及時的,Braze采取了一種戰略方法來利用作業隊列。
什麼是作業隊列?
典型的作業隊列是一種體係結構模式,其中進程向隊列提交計算作業,而其他進程實際執行作業。這通常是一件好事——如果使用得當,它將為您提供一定程度的並發性、可伸縮性和冗餘性,這是傳統請求-響應範式所無法獲得的。許多工作者可以在多個進程、多台機器甚至多個數據中心中同時執行不同的作業,以達到並發高峰。您可以分配某些工作節點在某些隊列上工作,並將特定作業發送到特定隊列,從而允許您根據需要擴展資源。如果工作進程崩潰或數據中心脫機,其他工作進程可以執行剩餘的作業。
雖然您當然可以應用這些原則並在小範圍內輕鬆地運行一個作業隊列係統,但當您處理數十億個作業時,問題就開始顯現(甚至出現問題)。讓我們來看看Braze在從每天處理數千個、數百萬個、到現在每天處理數十億個工作的過程中所麵臨的一些問題。
缺乏一致性是一個弱點
如果我們發送了一條消息,但在記錄我們剛剛發送了該消息的事實之前就崩潰了,會發生什麼情況?
這裏可能出現幾種不同的壞結果。首先,您可以重新安排失敗的作業並再次發送消息。這並不理想:沒有人願意兩次收到同樣的東西。相反,考慮完全不重新安排它。在這種情況下,我們的內部核算將是不正確的,因此歸因、轉換和所有其他類型的事情將不會正確向前發展。
我們如何解決這個問題?在編寫工作定義時,我們會認真考慮冪等性和重試行為。
當談論隊列時,等冪性意味著單個作業可以在任意點終止,重新排隊的作業可以整個重新運行,最終結果與我們隻成功運行了一次作業相同。這與我們選擇至少一次交付的重試行為密切相關。記住我們所有的作業都將至少運行一次,甚至可能多次,我們可以編寫冪等的作業定義,即使在麵對隨機故障時也能確保一致性。
回到我們的消息發送示例,我們如何使用這些概念來確保一致性?在本例中,我們可以將作業分成兩個部分,第一個部分發送消息並將第二個部分放入隊列,第二個部分寫入數據庫。在這種情況下,我們可以盡可能多次地重試任何一個作業——如果消息發送提供者關閉了,或者內部計費數據庫關閉了,我們將適當地重試,直到成功!
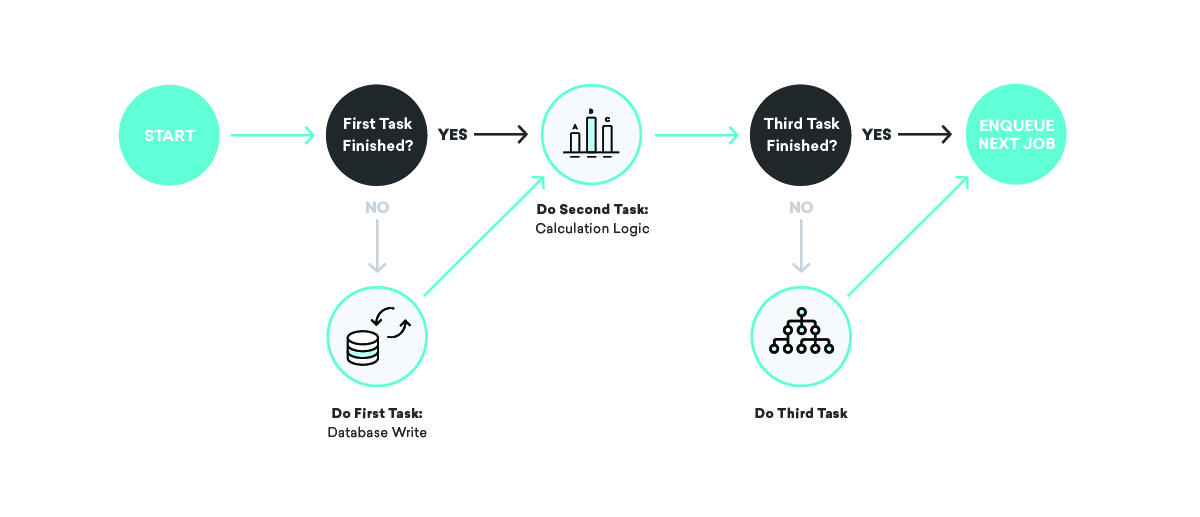
好籬笆造就好鄰居
當Global Gizmos的數據庫關閉時,我們的示例公司Consolidated Widgets的數據處理會發生什麼變化?
在這個場景中,如果我們的“至少一次交付”策略起作用,我們將期望Global Gizmos的所有數據處理作業都將不斷重試,直到它們成功。這太棒了——即使他們的數據庫壞了,我們也不會丟失任何數據。然而,對於Consolidated Widgets來說,情況可能就沒那麼好了:如果工作人員不斷地嚐試和失敗,他們可能太忙了,無法及時處理Consolidated Widgets的工作。
我們可以通過使用精心選擇的隊列名稱和根據需要暫停某些隊列來解決這個問題。在我們的工具帶中,我們可以以外科手術的方式減輕基礎設施部件上的壓力。在我們上麵的場景中,一旦我們知道Global Gizmos的數據庫關閉了,我們就可以暫停他們的數據處理隊列,直到我們知道它恢複了,確保一個特定的中斷不會影響任何其他客戶!manbetx万博全站客户端
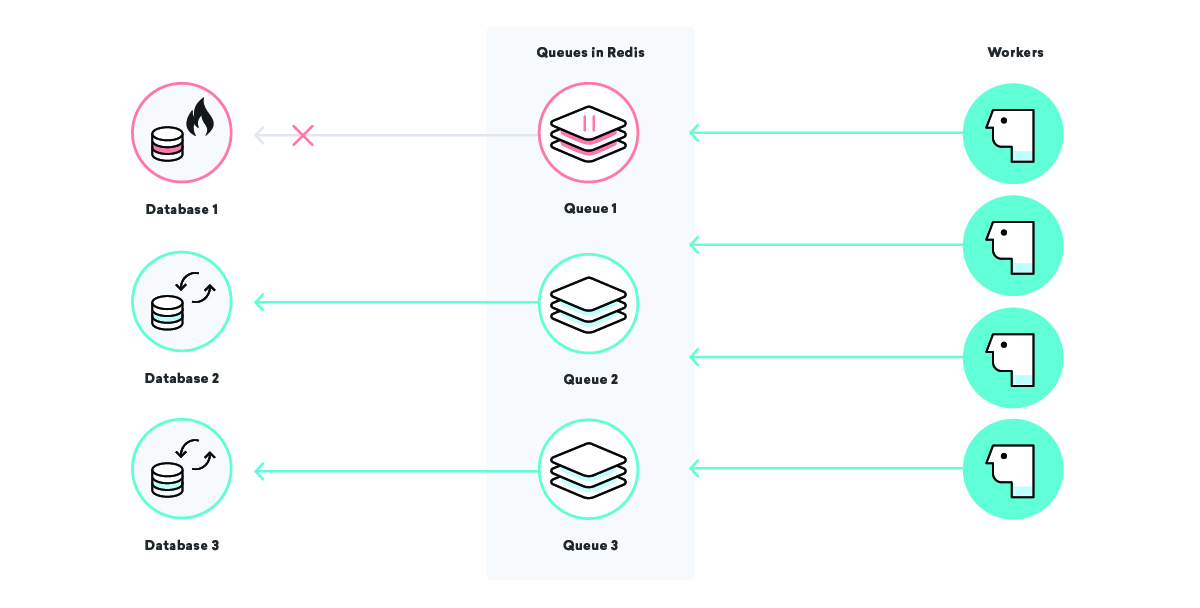
等待是痛苦的
如果Consolidated Widgets和Global Gizmos分別向5000萬用戶發送電子郵件活動,間隔5分鍾會怎樣?誰先走?
簡單的工作排隊係統有一個簡單的“工作”隊列,工人從中提取工作。一旦您有了各種不同的工作和工作類型,您可能會繼續擁有多種類型的隊列,每種隊列具有不同的優先級或從這些隊列中提取的不同類型的工人。在這種情況下,我們有各種用於數據處理、消息傳遞和各種維護任務的簡單隊列。
快進到當你每天發送數十億條個性化消息時,一個“消息”隊列不能解決問題——當隊列變得非常大時會發生什麼,就像我們上麵的例子一樣?我們會優先考慮那些最先到達的工作嗎?
我們的動態排隊係統試圖解決一種稱為作業饑餓的現象,即一個準備執行的作業在執行之前等待了很長時間,通常是因為某種優先級。在簡單的“消息傳遞”隊列中,優先級隻是作業進入隊列的時間,這意味著添加到大隊列末尾的作業最終可能等待很長時間。
當我們要對一個活動及其所有消息進行排隊時,我們不是將工作添加到一個大的“消息傳遞”隊列中,而是為這個活動創建一個全新的隊列,帶有一個特殊的名稱,以便我們知道它是什麼以及如何找到它。將作業添加到隊列後,我們獲取“動態隊列”列表,並將這個新隊列名稱添加到末尾。
通過采用這種策略,我們可以指示工作人員從“動態隊列”列表中選取動態隊列的名稱,然後處理該特定隊列上的所有作業。這使我們能夠確保信息以盡可能快的速度發送,並確保我們所有的客戶都得到同等的優先級。manbetx万博全站客户端
因此,這有其他好處,比如更高的緩存命中率和更少的數據庫連接,因為增加了特定工作者的工作位置。每個人都贏了!

總是有一個備份計劃
當數據庫關閉、一些隊列暫停、作業隊列開始填滿時會發生什麼情況?
有時,重要的基礎設施會在您身上消失。我們有輔助和備份,但促進備份基礎設施的時間幾乎從不為零。在整個應用程序基礎結構中擁有多層隊列對於減輕這類事件的影響非常有幫助。
我們采用的一個策略就是在設備上排隊。數以百萬計的設備有不同的應用程序使用Braze SDK,在這些應用程序中,我們利用隊列將數據發送到我們的api。
當我們的SDK提交該數據並由於某種原因失敗時,SDK將使用指數後退算法排隊重試,直到成功。這種策略將基礎設施或代碼故障的影響降到最低,因為設備將簡單地將自己的數據排隊,並在一切恢複在線時將其發送到Braze。

快速移動,不破壞東西
在一天結束的時候,我們的目標是發送高度專注的,個性化的消息比任何人都好,這包括快速行動、適應力強、把一切都做好。作業隊列是Braze基礎設施的核心,因此我們一直在觀察我們的性能,采用最佳實踐,並試驗新策略和先進技術,以在遊戲中成為最好的。
如果這種高性能、低延遲的係統工程在營銷自動化領域讓您感到興奮,那麼您絕對應該這樣做查看我們的招聘公告欄!







